データ読み込み
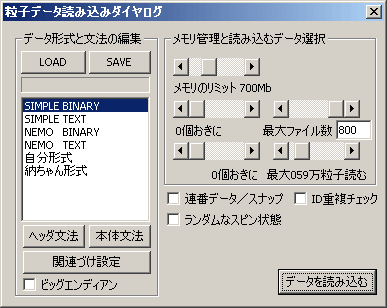
データ読み込みを実行すると、上のようなダイアログが現れます。このダイヤログで、読み込むデータのタイプを選択します。
連番データ/スナップ
チェック時には、時間進化するデーターを可視化するものとして連番ファイルを読み込みます。
チェックが外れているときには、ある一瞬のデーターを見るものとしてファイルを1つだけ読み込みます。
下のスライダーは、カメラ位置を決める際に何フレーム分使うかを決定します(後述)。
(たとえば10で設定すると、10箇所カメラ位置を設定できます)
連番でファイルを読み取るときには、ファイル名は、
whatevername000.拡張子
whatevername001.拡張子
whatevername002.拡張子
…
という形の連番にしておきます。
あまり推奨は出来ませんが、
whatevername.001
whatevername.002
…
という形の連番にも対応しています(拡張子が数字のみで構成されている場合に自動的に判別)
データ形式選択
- SIMPLEBINARY: 単純なバイナリ形式(後述)
- SIMPLETEXT: 単純なテキスト形式(後述)
通常は上の2つのうちどちらかを使用してください
- NEMO:TEXT形式のNEMO
- NEMO:BINARY形式のNEMO(開発中)
- 自分形式:開発者用の特殊なバイナリ形式
- 納ちゃん形式:開発者用の特殊なテキスト形式
文法編集
可視化を行うにあたって、アプリケーションにこれから読むデーターの文法をあらかじめ与えておく必要があります。
文法ボタンを押すと現れるダイアログで、SIMPLE TEXTと、SIMPLE BINARY の本体部分とヘッダ部分の文法を編集できます。 >>文法編集
- ヘッダ:データーファイルの先頭に、粒子数や時間などを書いておく部分です。
- 本体:粒子の位置情報や速度情報を収めた部分です。ヘッダに続いて書き込まれているものとします。
文法は、.grmの拡張子を持つファイルとして、保存と読み込みが出来ます。
粒子ID
粒子数の増減がある場合には、ある粒子の連続性は、IDを見て判断しています。
同一の粒子は、すべてのファイルで同一のIDをつけてください。
また、違う粒子同士には、全て違った番号をつけてください
ファイル1にIDが1,2,3の粒子が3つ、
ファイル2にIDが2,3,4,5の粒子が4つ存在する場合、粒子1は消滅し、粒子4,5が新たに生成されたとみなします。
粒子IDを読み込まない場合には、データー上の粒子の番号そのものが粒子のIDとされます。
ビッグエンディアン
バイナリ形式のファイルの書き方は、cpuの種類によって違う場合があります。
ビッグエンディアンに対応したマシンからのデータを読み込むには、このチェックをonにしてください。
メモリのリミット
粒子データの保持用に使用するメモリの上限を設定します。マシンに積んでいる以上のメモリを利用しようとすると、HDDとのスワップが発生して動作が極端に遅くなります。
本当は自動判別したいのですが、今のところ手動設定です。
タイムランウィンドウのオンメモリ情報>>
連番データ/スナップ
ファイルを連番で読み込んで、時間進化を見るときにはチェックします。
チェックをはずすと、データーを1つだけ読み込んで、ある一瞬のスナップのみを見ることになります。
ID重複チェック
データ読み込み時にIDの重複がないかチェックして、重複があった場合に警告を出すようにします。
ランダムなスピン状態
粒子のスピン情報の読込機能はまだ未対応です。ただし、全ての粒子が同じ方向を向いていては映像が不自然な場合に、このチェックを入れることで、粒子の向きをランダムにふることが出来ます。
データを読み込む
読み込むファイルを決定して、データ読み込みを開始します。
連番ファイルの先頭を選択して開いてください。
ドラッグ&ドロップでもファイルを読み込むことが出来ます。
関連付け設定
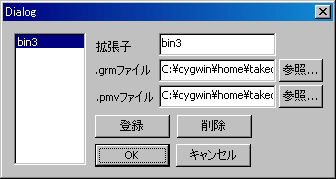
毎回文法ファイルや表示設定ファイルを読むのは面倒なので、拡張子に応じて自動的に文法ファイルと、表示設定ファイルを読むことができるようにします。
右側のエディットボックスで、拡張子と結びつく文法ファイルや表示設定ファイルを入力し、登録することで関連付けを設定できます。
登録された拡張子を持つファイルを読み込む際に、自動的に関連した文法ファイルや、表示設定ファイルを読み込みます。

戻る