可視化を行うにあたって、アプリケーションにこれから読むデーターの文法をあらかじめ与えておく必要があります。
- ヘッダ:データーファイルの先頭に、粒子数や時間などを書いておく部分です。
- 本体:粒子の位置情報や速度情報を収めた部分です。ヘッダに続いて書き込まれているものとします。
どちらも、ダイヤログを使って文法を編集することが出来ます。
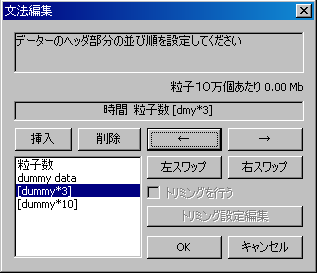
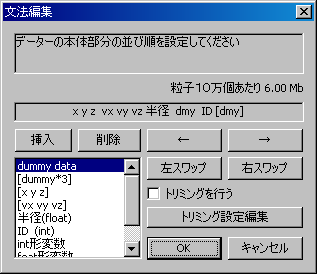
中括弧[ ]を左右ボタンで動かして、スワップボタンで位置の入れ替え等を行います。
視覚化に不必要なデータを含んだデータの場合には、不必要な情報の位置にdummyを挿入してください。
- SIMPLE TEXT
上の例の場合には、ヘッダとして
時間(改行)
粒子数(改行)
という2行が存在し、その後何らかの可視化には不必要なデータが3行続いているものとします。
ヘッダに続いて、粒子1つにつき1行毎に
x y z vx vy vz r 何らかのデータ ID 何らかのデータ (改行)
x y z vx vy vz r 何らかのデータ ID 何らかのデータ (改行)
…
というような形のデータであるとして読み込みを行います。
データとデータの間は空白(スペース)で区切られているものとします。
また、データの先頭に#のある行は、コメント行として無視します。
- SIMPLE BINARY
上の例の場合には、ファイルの先頭にヘッダとして
時間(float) 粒子数(int)
の計8byteが存在し、それに続いてなんらかの不必要な情報が(floatまたはint型)3つ分の計24byteが存在するものとします。
ヘッダ部に続いて次のように本体が
x y z vx vy vz rの順で7つのfloat形(4byte)が続き、その後にdummyとしてfloat形(4byte)の何らかのデータ、int型(4byte)の粒子のID、最後にfloat形(4byte)の何らかのデータがあり、次の粒子のx y z…
と書き込まれているものとして、データの読み込みを行います。
粒子ID
粒子数の増減がある場合には、ある粒子の連続性は、IDを見て判断しています。
同一の粒子は、すべてのファイルで同一のIDをつけてください。
また、違う粒子同士には、全て違った番号をつけてください
ファイル1にIDが1,2,3の粒子が3つ、
ファイル2にIDが2,3,4,5の粒子が4つ存在する場合、粒子1は消滅し、粒子4,5が新たに生成されたとみなします。
粒子IDを読み込まない場合には、データー上の粒子の番号そのものが粒子のIDとされます。

戻る