データを読みこむために、Data Loader ダイアログでこれから読むデータがどのような形式のものかを設定しておきます。
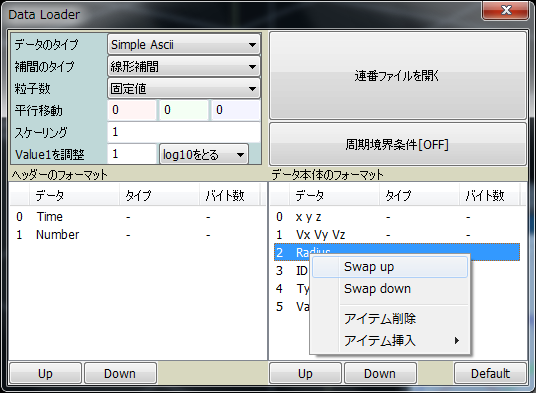
データのタイプを設定します。バイナリーかテキスト(アスキー)かを設定します。
補間のタイプを設定します。
シーン中のデータ数が固定かどうかを設定します。もしも粒子数の増減がある、もしくはシミュレーション上の理由で粒子の順番が入れ替わったりしていなければ、こちらを選択します。
このモードでは、すべての時間ステップでのn番目の粒子は同一の粒子とみなすので、補間の計算の時に余計な計算の必要がなく少し速くなります。
粒子数の増減があったり、順番が入れ替わったりする場合には、タイムステップmとm+1のn番目の粒子が同一の粒子である保証がないために、各粒子のIDを用いて連続性のチェックを行います。同一IDの粒子を探すという操作が必要なために、補間の計算が遅くなる可能性があります。
シミュレーションで使う数値の典型的なスケールや位置は、そのコードに依存します。
もし、典型的な数値が大きすぎたり小さすぎたりする場合や(106や10-6など)、中心が原点からずれているような場合には、操作が行いづらくなります。
このパラメーターによって、データ読み込み時にスケールを変更したり、平行移動させておくことができます。Scalingのパラメータは、位置、速度、半径のパラメーターに影響をします。
大きなポリゴンを猛烈に描画すると、グラフィックボードへの負荷が非常に大きくなります。
不注意なパラメータ設定によって、たとえば画面いっぱいのポリゴンを107回繰り返して描くようなこともあり得ます。
Zindaiji3ではそういった場合のチェックは行えないので、そうした危険なシーンのパラメータにしないように注意をしてください。
「Value1を調整」のパラメータを使って、VALUE1 のスケーリングや、logを取ることができます。
データ読み込み時にlogの計算をするために、毎ステップlogの計算をする必要がなく表示は遅くなりませんが、カラーカーブの表示などでは若干不便ではあります。
もし元々のVALUE1が負の値であれば、0を返します。
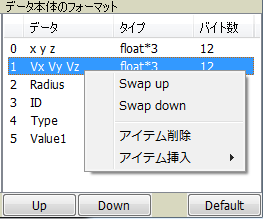
文法の「X Y Z」や「PARTICLENUMBER」などは、フォーマットエディタを使って順番を変更することができます。
文法のアイテムは、ボタンか、右クリックメニューから上下に動かして変えられます。また、右クリックメニュー上からアイテムの削除や挿入を行えます。
また、右下のDefaultボタンでデフォルト状態に戻すことができます。
現時点では、エラーチェックを実装していないので、必須なデータ「X Y Z」や「PARTICLENUMBER」などが無い状態で読み込むこともできます。実行結果は不明(Segmentation faultとか…)なので、注意してください。
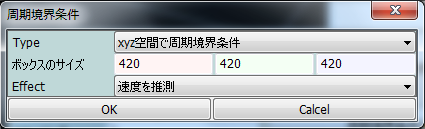
周期境界条件の箱の中のシミュレーションでは、1ステップの間に端から端まで粒子が移動することができます。
そのような粒子を素直に補間をすると、一瞬で端まで飛んでゆく高速な粒子として表示されてしまいます。
周期境界条件を設定すると、一ステップの間に大きく移動する粒子は、境界を跨いだとみなして、境界の反対側のミラー粒子の位置への補間を行います。(又はその成分の速度を0にします)
Zindaiji3では、ボックス型の境界のみに対応して、任意形状の境界などには対応していません。
また、この機能が働くには、箱の大きさの情報が必要になります。
差動回転するボックスには、現時点では対応をしていません。